No items found.


Match commodities by fetching key information in large amount of data
Handling large amounts of data and fetching useful information.
Python, JSON, VSCode, Algorithm-- tree
Task background:
Mapping 2385 tax codes from specific categories in avalara.xlsx file as much and accurately as possible with the commodity in the UNSPSC.csv file.
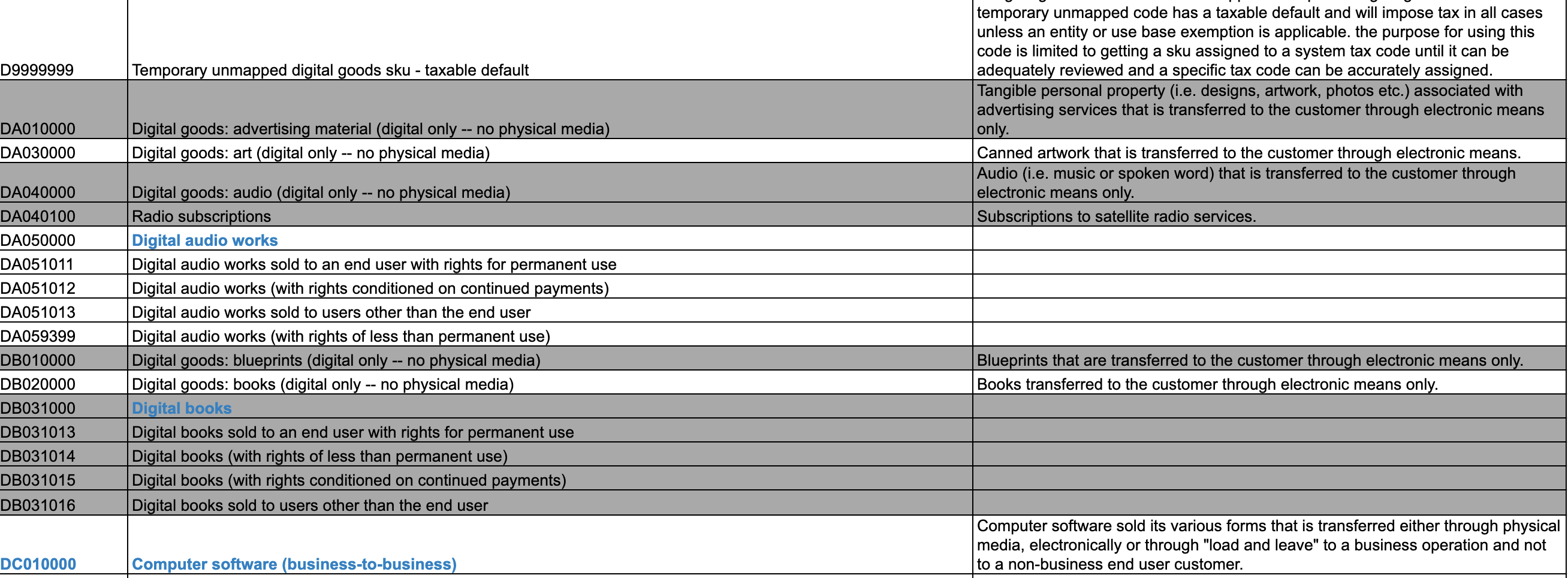

Preparation:
- Device: MacBook Pro with M1 pro chip
- Software and IDE: PyCharm, VScode, excel, google docs.
- Language: Python
Attempts Overview:
We have 5 attempts of mapping: 2 unsuccessful attempts without coming out with valid matches, 2 attempts with valid matching outcomes, and 1 final match(all the attempts run on the same MacBook Pro with an m1 pro chip):
Failed Attempts 😕:
Strategy
Implements & Improvements
Results & Findings
Static level-to-level mapping & searching:
v1.1
Trying to map the general tax code with segment-level, then search in its branches.
Both failed, as most of the tax-codes general_types do not have matches in segment-level
v1.2
Wrap up all words in one general tax code, use it as a “description” for that general_type and try to map it with a segment. Then search in this segment.
v2.1
Trying to map every specific commodity with every specific type. 835/2547 tax code processed in 2.5 hours.
Too time-consuming, would need approximately 7.5 hours to complete, we give up.
Attempts with valid outcomes 🙂:
Dynamically switch between brute force searching and level-to-level mapped searching.
Mapping rate: 1266/2385 = 53%
Running time: 253s
Accuracy score: 40% accuracy
(8 good -12 bad out of 20 random samplings)
v3 + cosine-similarity grading
Upgrade similarity-grading strategy with cosine-similarity.
Mapping rate: 1716/2385= 72%
Running time: 152s.
Accuracy score: 35% accuracy
(7 good -13 bad out of 20 random samplings)
Final Version 🥳:
+ cut off bar for cosine-similarity
Set cut_off_bar for similarity-grading strategy.
Replace manually pick deny_words_list with generated deny_words_list.
Mapping rate:1543/2385= 65%
Running time: 33 minutes
Accuracy score: 60% accuracy
(12 good -8 bad out of 20 random samplings)
Technical Discussion
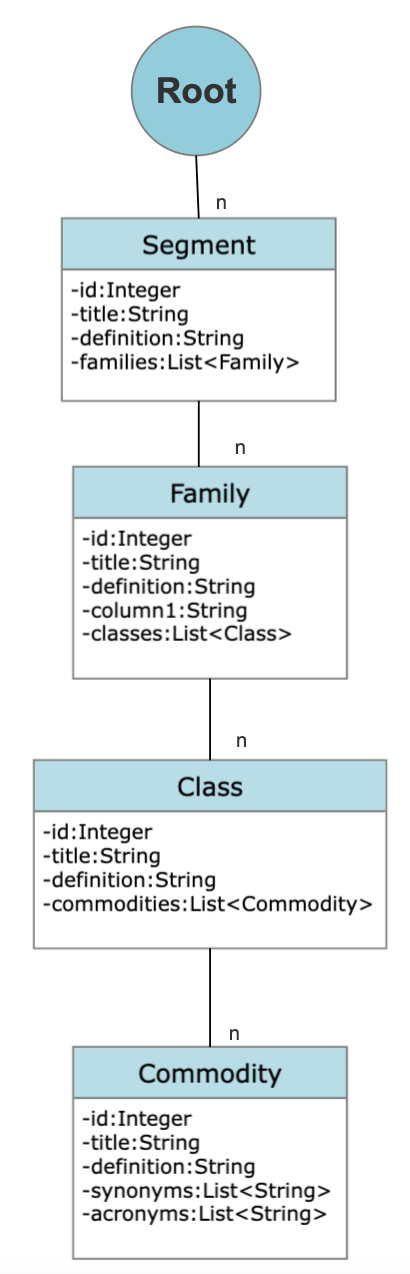
Data Representation – tree structure:
Inspired by the manual analysis
After conducting a manual analysis of the two files, we came up with the idea of pre-processing all the data in a tree structure. This will eliminate duplicate searches and save time. The reason for this choice is that we found the target commodity is located at the deepest level (the leaf level) of the tree. The data structure is hierarchical, with one segment having multiple families, each family having multiple classes, and each class having multiple commodities.
Our first thought on searching was to locate the target in a specific segment, which would minimize the search range and allow us to conduct the same search within the same segment for specific categories under one general category in the avalara.excel file. This would also apply to the Family and Class level.
Using a tree structure also allows us to switch between different levels of the data structure, which would be helpful later on.
Preprocess data into a tree structure
We do a similar data process on both UNSPSC_English.csv and avalara.xls – to organize two files of data into a tree structure.
For UNSPSC_English.csv: the segment is the parent node of family, and family is the parent node of class, and class is the parent of the commodity (see the above pic)
For avalara.xls, parents are the generic categories(text in blue) and children are the specific categories.
Implementation of the tree structure with codes
The tree_unspsc.py file in our folder is used to process the UNSPSC file into a tree structure. The tree_avalara.py file is used for the same purpose, but for the avalara file.
We have chosen to use python for our programming language as it is efficient for data analysis and has strong libraries that make it easy to implement.
In the process of converting the UNSPSC file into a tree structure, we import the defaultdict from the collections, which is an improved dictionary. We also import the reader from the csv module to help read the UNSPSC.csv file and the json module for data visualization.
We then create classes for the Segment, Family, Class, and Commodity, with each class having fields for id, title, and definition. The child-level is written into a dictionary. For example, the Segment class is shown below (the complete code can be found in the UNSPSC_tree_data_process.py file):
class Segment:
def __init__(self,id,title,definition):
self.id = id
self.title = title
self.definition = definition
self.family_dict = defaultdict(Family)
After that, we go through each row in the UNSPSC.csv, and parse each line’s data into segment, family, class, and commodity separately.
Then we start building the tree. As we notice there may be some key data missing, we handle this case by skipping it rather than correcting or completing it (because we think the latter is inefficient and hard to implement). We build the tree level by level– checking if the item’s segment is already in the root, if not, that means we come across a new segment, we wrote it into the root’s dictionary, if so, that means we come across the family within the same segment, we go check its items in child level– family, do the similar operations. We finished on processing the file till all commodities share the same class level, are added into class.commodities dictionary, all class share same family level, are added into family.classes dictionary, all family share same segment level, are added into segment.families dictionary (code snippet below):
if curr_segment.id:
if curr_segment.id not in root.segments:
root.segments[curr_segment.id] = curr_segment
else:
curr_segment = root.segments[curr_segment.id]
else:
continue
if curr_family.id:
if curr_family.id not in curr_segment.families:
curr_segment.families[curr_family.id] = curr_family
else:
curr_family = curr_segment.families[curr_family.id]
else:
continue
if curr_class.id:
if curr_class.id not in curr_family.classes:
curr_family.classes[curr_class.id] = curr_class
else:
curr_class = curr_family.classes[curr_class.id]
else:
continue
if curr_commodity.id and curr_commodity.id not in curr_class.commodities:
curr_class.commodities[curr_commodity.id] = curr_commodity
In processing the avalara file into tree structure, we use a similar library and technique to deliver the tree structure, where the parent is the generic category and the child is the specific category.
The process on two raw files is completed. We start to implement Searching and Matching. Following is the pseudo json file for giving you an insight of our data structure:
{
"segments": {
"10000000": {
…,
"families": {
"10100000": {
…,
"classes": {
"10101500": {
…,
"commodities": {
"10101501": {
…,
},
"10101502": {
…,"
},
"10101504": {
…,
},
"classes": {
"10101600": {
"commodities": {
"10101601": {
…,
},
},
"classes": {
"10101700": {
"commodities": {
"10101701": {
…,
},
…,
"families": {
"10200000": {
"classes": {
"10201700": {
"commodities": {
"10201701": {
…,
},
…,
"families": {
"10300000": {
…,
Search and Match
In our search and match process, we have 5 attempts, which include 2 unsuccessful attempts without coming out with valid matches, 2 attempts with valid matching outcomes, and end up getting 1 final match with a 65% mapping rate and 60% accuracy (estimated)!
Version 1: Static level-to-level mapping & searching
This is our first attempt at mapping the general tax code with segments and then searching in its branches. We wanted to do this because if we can locate a general category in a segment, that means the specific categories under that general category can all be searched and matched in the same segment, which could be efficient.
v1.1
In this version, we tried to map the general tax code with segments and then search in its branches. However, there were few matches generated.
v1.2
After reflecting on the results from v1.1, we found that it was difficult to generate matches. We suspected that this was because the information in the general tax code was too limited to match the segments. In an attempt to address this, we tried wrapping all the words in a general tax category and using it as a "description" for that general category and then mapping it to a segment. We believed that this would provide enough information to locate a segment. However, there were still few matches generated. We ended up trying other implementations.
Version 2: Initial Bruteforce mapping
After our first failure, we decided to start over and use a brute-force search method to see how many matches we could generate. We tried mapping every specific commodity to every specific type, but this turned out to be incomplete and time-consuming. It would have taken at least 7.5 hours to finish, so we knew we needed to find a more efficient solution.
That's when we realized the importance of efficiency and decided to improve our initial brute-force search. We implemented a dynamic search in our third version, which significantly reduced the running time.
Version 3: Dynamic brute force searching
Generally speaking, we first try to establish a level-to-level match. If such a match is found, we only need to search the specific branch for a mapping. If there is no such match, we rollback to a higher-level branch and search there. If there is still no match at any level, we use brute force to search every data point.
To be specific, we first try to match general categories with segments. If there is a successful match, use this segment for all specific types in the general categories. If it is not successful, search all families from all segments. Similarly, for each specific type, try to pair it with families, classes, and finally commodities. If there is a match at a certain level, only search this branch. If not, search all possible branches.
pseudocode:
for general_types in avalara_root:
max_segment = best_match(general_types, segments_from_unspsc)
for specific_type in general_types:
if max_segment:
family_candidates = [max_segment.family]
else:
family_candidates = ["segment.family from all segment"]
for family in family_candidates:
max_family = best_match(specific_type, family)
if max_family:
class_candidates =[max_family.class]
else if max_segment:
class_candiates = [family.class for family in family_candidates]
else:
class_candiates = ["all class from all segment" ]
for class in class_candidates:
max_class = best_match(specific_type, class)
if max_class:
commodity_candidates =[max_class.commodite]
else if max_family:
commodity_candidates =["all commodities from max_family"]
else if max_segment:
commodity_candidates =["all commodities from max_segment"]
else:
commodity_candidates =["all commodities from all segment" ]
for commodity in commodity_canditates:
max_commodity = best_match(specific_type, commodity)
if max_commodity:
res.append((sepecific_type: commodity))// get a matched data point
else:
print("no commodity found for this tax-code)
best_match() function is implemented by several helper functions in real code, returning one best match output for the desired types of data. ex:
best_match(B{type:specific_type}, A{type:family}) would go search all commodities in A.commodities, try to match it with B, and return the one{type:commodities} with highest similarity-score
Output examples:
In the following example, we were unable to find a match for the {general_type – segment} in any of the families. Therefore, we conducted a search in all families and classes for taxCode = PH050859. Despite our efforts, we were unable to find a good match in these categories. As a result, we were forced to conduct a brute force search of all commodities, which took 1.18 seconds to complete. Fortunately, this search yielded a valid match. While brute force search may take longer to complete, it can sometimes provide a valuable match that is not captured by the level-to-level search method. Therefore, it cannot be totally abandoned.

In the example below, we do not find a match for{general_type —segment }. However, we do find matched families/classes, so we only search within those branches and find a match in just 0.001 seconds. This demonstrates that using a level-to-level search approach can save a significant amount of time. By carefully determining the validity of a level-to-level match, the search can still be accurate.

Version 4: Dynamic brute force searching + cosine similarity grading
This version is an update based on the version 3, where we adopt the cosine similarity grading, to improve our scoring system on making a judgment if two items can be matched.
We come up the improvement idea by the following questions step by step:
How should we compare two lists of words and determine their similarities ?
Our initial idea is to compare the similarity of two lists of words, A and B, by calculating the number of words in both lists and dividing that by the product of the lengths of A and B. The resulting score will indicate the degree of similarity between the two lists, with a higher score indicating a higher degree of similarity. In formula form, the score is calculated as follows:
score =number of words in both A and Blen(A)* len(B)
Why divided by len(A)*len(B)?
To properly compare the similarity of two word lists, we need to normalize the score based on the lengths of the lists. This is because longer lists will naturally have more words in common, so we need to adjust the score to account for this. Additionally, we need to consider the symmetry of the lists, as well as the fact that duplicated lists should have the same similarity score.
To achieve this, we can use the square of the length of both lists as the divider for the score. This ensures that the score is properly normalized and accounts for the symmetry of the lists. For instance, if we have two 100-elements-word-lists with 2 words in common, they will have a lower similarity score than two 10-elements-word-lists with 2 words in common.
Of course, we can further argue the specific formula for the divider, such as using len(A)*len(B) instead of len(A)^2 +len(B)^2. However, our initial design does not have the necessary support to make a definitive decision on this matter. Therefore, we have sought out alternative solutions and found hints from Professor Lama Hamandi that can help improve our approach.
Improved idea – cosine-similarity:

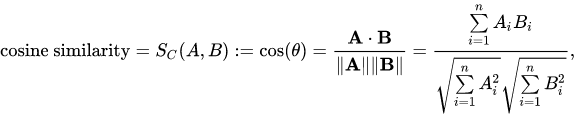
The cosine-similarity metric is used to measure the similarity between two documents. By creating a vector graph with the common words from both documents as the x and y axes, the similarity can be visualized by the angle between the two vectors. The smaller the angle, the more similar the documents are. Additionally, the degree of similarity can be represented numerically using a cosine value, where a value closer to 1 indicates a higher degree of similarity. For example, a cosine value of 0.95 for a 17 degree angle indicates a high level of similarity between the documents.
So we apply cosine-similarity metric to our similarity-grading system by using python build-in library Counter obj:
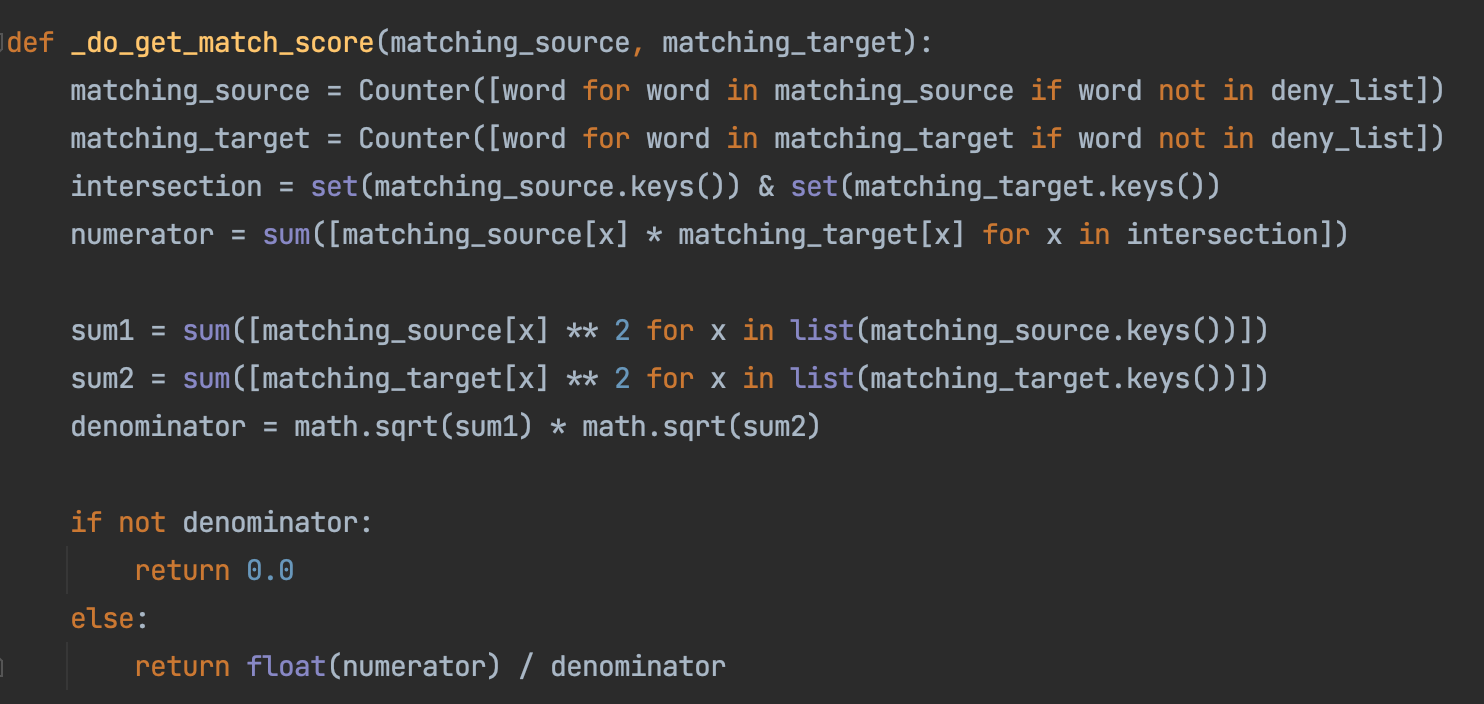
After implementing our new similarity-grading strategy, we have seen an increase in the number of matching outputs, going from 1266 to 1716. While this is a positive outcome, we have noticed a slight decrease in the matching accuracy.
Version 5: Version 4 + cut off points for cosine similarity + generated deny words
Our final version, updated from version 4, is implemented by solving the questions we raised among the attempts. The questions include: Which words should be ignored in a specific comparison? How about removing the high_freq words in both data sets? By solving these two questions, we come up with the final version with a cut-off score and generate deny words lists.
We came up with the cut-off points for cosine similarity as we thought if the best match score is below the cut-off points, we can discard all potential candidates as they are not similar enough. The cut-off score varies depending on the level of the match, ranging from 0.25 to 0.22. We implement this approach because higher level branches contain more information than longer word lists, and choosing the wrong higher-level branches would have more serious consequences than incorrect lower-level branches. The cut-off score is determined through testing and ensures that most matches occur in detailed branches, while allowing for some fuzzy tax codes to be searched at higher levels, even prue brute force.
Additionally, the cut-off score takes the overall running time into consideration. If the cut-off bar is set too high, most searches would require brute force and take hours to complete. On the other hand, if the cut-off bar is too low, the search would finish in a few minutes, which does not use full computation resources for a non real time searching. Currently, our search is completed within 30 minutes. Around 30% general type tax codes would get a matched segment level, 60 % specific types would fall into some level-to-level match, only 10% tax-code needs to be brute force searched, and takes most of the computation time. In the future, we could further explore if there is a more scientific way to set up those cut-off points, or tweak it based on different accuracy-running time requests.
Another question we need to think about is:
Which words should be ignored in a specific comparison?
It is clear that some words in the list are meaningless and should be ignored during the comparison. Initially, we manually selected words such as "the," "a," "or," "to," "and," and the empty string to use in the comparison because some information was missing. This approach worked, but we wanted to ensure that we were using the best possible word list.
To improve our method, we came up with the idea of using the most frequent words in each dataset as indicators of meaningless words. We compiled all the words in both files and counted the frequency of each word, sorting them in descending order. This allowed us to identify the most commonly occurring words and exclude them from the comparison. By using this approach, we were able to confidently determine the optimal list of words to use in the comparison.
Following list is what we get (which are the most frequent words in files):
[' ', 'of', 'approach', 'percutaneous', 'or', 'with', 'and', 'open', 'endoscopic', 'right', 'left', 'device', 'substitute', 'the', 'tissue', 'in', 'non', 'gmo', 'organic', 'dried']
[' ', 'nan', 'and', 'to', 'the', 'a', 'or', 'for', 'of', 'software', 'that', 'products', 'is', 'food', 'with', 'services', 'sold', 'business', 'are', 'medical', 'computer']
After conducting our analysis, we discovered that some of the words are considered "meaningless" while others are not. For example, the word "endoscopic" refers to a specific type of medical examination equipment, and although it appears frequently, it is not meaningless. Therefore, we should not remove it from the analysis. Additionally, we noticed that the word does not appear in the avalara file.
How about removing the high_freq words in both data sets?
Here is the list of first_100th_high_freq words that appears in both data sets:
[' ', 'and', 'to', 'the', 'a', 'or', 'for', 'of', 'that', 'with', 'services', 'are', 'related', 'as', 'in', 'by', 'on', 'non', 'other', 'health', 'this', 'code', 'from']
Which seems decent to use! As it is generated from the files and cross-examined by each other, we believe it is safe enough to use in this project. It is also more convincing than the manually picked deny_list.
Limitations and future improvements:
How to “reject” a promising mapping?
After reviewing the files, we have identified several matchings that are difficult to reject with our current strategies. For example, the pairing of "Salad bar" and "food: salad" share many similar keywords, but refer to different concepts. Similarly, "pet food supplies" and "pet food bowls supplies" may be closely related, but again refer to distinct items. This issue is particularly prominent in the case of "Medical care products" and "facial care products".
To address this challenge, we plan to explore the use of natural language processing (NLP) and sentence structure recognition techniques. These tools will help us accurately distinguish between similar but distinct concepts, improving the overall accuracy of our matching system. We are committed to continuing to work on this project and finding solutions to improve our performance.
How to deal with ignored negative adjectives?
The following map: "taxCode=PF052146, specificTypeName=Beverage / nutrition label / non-carbonated / vegetable juice = 100% / ready to drink (rtd), information=nan" is mapped to: "Carbonated beverage dispenser 48101701". In this case, our algorithm processes "non-carbonated drinks" as [carbonated, drinks], ignoring "non" as a high-frequency and meaningless word in both files. This allows us to match non-carbonated drinks with soda drinks.
Additionally, an example of opposite ideas being matched is the high similarity score between "gluten-free bread" and [gluten, bread]. While our algorithm currently does not address this issue, we may consider revamping the string split process to retain negative adjectives and incorporate a variable to track the positive or negative nature of the word list for improved performance in the future.
Conclusion
After several unsuccessful attempts, we developed a dynamic brute-force searching algorithm that significantly reduces time cost without compromising searching accuracy. Additionally, we enhanced our similarity-grading strategy by implementing the cosine-similarity algorithm. We also adjusted the cut-off bar for the similarity score to further improve the matching accuracy. The searching depth in the dynamic brute-force searching algorithm can be controlled by this cut-off bar if necessary. Furthermore, we used a generated deny_word_list to replace manually picked deny words, making the entire searching process more reliable. We ended up achieving a mapping rate:1543/2385= 65%, with running time on mackbook pro with m1 chip: 33 minutes and accuracy score: 60% accuracy (12 good -8 bad out of 20 random samplings).